
This post was authored by Jan Schenk, SurveyCTO super user and founding director of ikapadata, a Cape Town, South Africa-based survey research and data science company whose aim is to make data accessible, tangible, and actionable. This post was originally published on Medium.
One of the most underrated aspects of survey questionnaire design and form development is the naming of variables, which can originate in the naming of individual fields in SurveyCTO form design. For many survey practitioners, it might just be an afterthought, yet to me it is one of the fundamentals that separate well-designed and thoughtful surveys from mere data collection exercises. In the same way a good carpenter will put equal attention, detail, and effort into the hidden parts of a well-designed cabinet—such as the joints, hinges, and interior finishes—a good survey practitioner should spend considerable thought on the variable naming conventions in a questionnaire.
A good naming scheme can help structure the dataset and encourages one to think about the different ways in which the data will be analysed later. In fact, anyone who will be working with the resulting dataset at some point will have to deal with the variable names; making it easy for them encourages more people to actually use the data for their own analyses.
Choosing between question numbers and descriptive names
Most surveys use one of three methods for naming variables: cryptic codes, question numbers (e.g. “1”, “2”, “3” or “A1”, “A2a”, “A2b”) or descriptive names (e.g., “gender”, “age”, “employment”). There is absolutely no good reason to use cryptic codes other than to confuse and irritate anyone expected to work with the data, so we will just ignore that option. The debate between question numbers vs. descriptive names is less clear-cut though.
Question number variable names
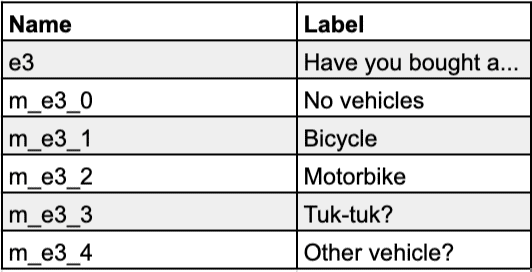
Defenders of the number method often mention the usefulness of question numbers for navigating questionnaires and referring to questions during the development of the questionnaire and training of enumerators; one can simply call out “Go to question 15” to a room full of enumerators in training, and everybody knows more or less where to find the question in the printed version of the questionnaire. I also heard more than once from a client that question numbers would make it easier to find variables in a dataset.
Descriptive variable names
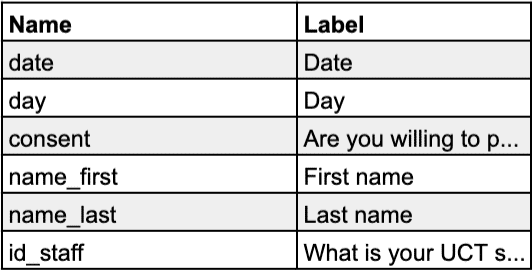
I do not really buy the second argument—in my opinion, a well-structured dataset with descriptive names is easier to navigate than a numbered one—but if there is one point I would concede to the proponents of the number method, it is the one about usefulness during training. Other than that, I believe that there are enough points in favour of a descriptive naming scheme that make it superior to numbering:
- Descriptive names help to structure the questionnaire and dataset. The careful use of pre- and suffixes helps to indicate which variables belong together, either thematically (e.g., “health_selfcare”, “health_medicine”) or by type (e.g., “awareness_likert”, “understanding_likert”), which makes it easier to understand the questionnaire when looking at it in XLSForm format (a spreadsheet design) and the dataset when looking at it in tabular format or as a list of variables.
- Questionnaires can change a lot during the development phase or over time if they are used over multiple survey rounds. This can quickly become messy with numbered questionnaires; adding or dropping a variable means that all subsequent variables also need to be renamed if one wants to keep a perfect sequence, which is especially annoying if you have an XLSForm with lots of dependencies in calculations and relevances, and it creates havoc in the scripts of data analysts who have already worked with the old names. To avoid this scenario, researchers sometimes revert to “extending” question numbers, and one ends up with variable names like “Q13”, “Q14a”, “Q14b”, “Q15”, “Q16”, “Q17a”, “Q17b”, “Q17c”, which go against the possible only advantage a numbered questionnaire has over descriptive variable names: intuitive navigation for printed questionnaires.
- The same descriptive variables names can be reused across different surveys, making it easier to reuse parts of mobile forms, recycle quality control backends, and run similar types of analyses across multiple surveys. Descriptive variable names make form development, scripted data analysis, and backend development more pleasant and less error-prone. Arguably, one does not have to be a statistics wizard to understand what the command tab gender if age < 25 means, whereas tab a26 if a28 < 25 requires one to look for the variables in a codebook of some sorts.
Helpful rules for naming descriptive variables
While there is no established standard for naming descriptive variables, we at ikapadata follow some best practices to keep variable names meaningful, useful, and consistent. At the most basic level, we follow the Stata conventions for variable names because we, as well as many of our clients, work with survey data primarily in Stata. However, if you and the people you work with are more familiar with another statistics package or programming language, you should probably stick to their conventions.
We define a name as a sequence of one to 32 letters (e.g., A–Z and a–z), digits (e.g., 0–9), and underscores (_). The first character of a name must be a letter or an underscore in SurveyCTO. We recommend, however, that you not begin your variable names with an underscore.
Beyond that, we have the following rules:
- Keep it lowercase: This also follows Stata (and other) conventions; it just takes the guesswork out of the lower- vs. upper-case debate.
- As short as possible, as long as necessary: The variable name should be descriptive enough to evoke a clear association with the item it represents, but not longer than it needs to be. For example, “brand” is arguably a better variable name than “brand_name”.
- Avoid abbrevs.: Unless it is a common abbreviation used in other survey datasets (e.g., “hhsize” for household size), it is usually better to write out variable names. It generally makes it easier to remember them, less ambiguous, and easier on the eye in scripts.
- Short and sweet and to the point: Enough said.
- Pre- and suffixes to structure the dataset: Pre- and suffixes are a great way to group variables thematically or by “type”. For example, a group of Likert-type scales for health-related items can be prefixed with “health_”, such as “health_smoking”, “health_nutrition”, “health_sports”. Similarly, attitudinal variables sharing the same values can be suffixed with “_attitude”, such as “patriarchy_attitude”, “religion_attitude”, “feminism_attitude”. At least in Stata, this will allow the analysts to quickly refer to whole groups of variables using an asterisk, as in foreach var of varlist health_*…. It is also helpful to use prefixes to flag variables that you would like to drop later, such as calculation fields that are only useful for form-building purposes. We use the prefixes “calc_”, “note_”, and “label_” to this end.
- Underscores for compound variable names: Combining multiple names by using upper-case letters (“nameEmployer”), hyphens (“name-employer”), or periods (“name.employer”) might work in some languages and platforms, but if you want to use a Stata-friendly naming scheme, you should use underscores and all lowercase (“name_employer”) instead. Be consistent with the pattern used for compound variables (e.g., “name_mother”, “name_father”, “age_mother”, “age_father”).
- The other exception: There is one type of compound variable name where an underscore does not work well: other variables capturing open-ended responses after a selection of “Other, specify” (or similar) has been made. The problem is that multi-select fields (select_multiple fields as they’re called in SurveyCTO) usually result in a series of dummy (0/1) variables in the dataset, and they are using underscores for differentiation. For example, the respondents might make the following selection as a response to the question “Which of these assets do you own?”: 1. Bicycle ✅ 2. Microwave ❌ 97. Other ✅, resulting in asset_1==1 asset_2==0 asset_97==1 in the dataset. It would then be tempting to name the variable for the open-ended question “What other asset do you own?” “asset_other”, but this would cause problems if one wanted to group the asset dummy variables for analysis. For example, mrtab asset_* would result in an error as the command mrtab cannot handle a combination of numeric and string variables. To avoid this, the rule is to just concatenate the variable name and “other”, as in “assetother” (without an underscore).
- No double-bookings: Multi-select fields resulting in a series of dummy variables (see previous point) are also a potential source of conflict with other variable names. If you name your multi-select field “asset” and you have another field named “asset_1”, you will have problems with duplicate variable names later on.
- Consistency is key: As much as possible, try to recycle names for common variables across different questionnaires and stick to commonly used names, especially if the questionnaires are part of the same survey or study. For example, it should not be “gender” in the household questionnaire and “sex” in the individual questionnaire.
These rules are not exhaustive and leave a lot of flexibility for personal variable naming preferences. But at the very least they should provide some ideas on how to avoid old and tired question numbers in questionnaires and replace them with wonderfully meaningful and descriptive variable names. Happy variable naming!
Field names do have some rules in SurveyCTO forms, similar to those for form IDs, and some of which the author addresses. Field names must be unique, start with a letter, and cannot include any spaces or punctuation. Sticking to letters, numbers, and underscores will have predictable results, such as helping you avoid a long range of disallowed special characters. Field names are not limited in length, but as the author mentions, overly long field names can be a source of difficulty later. For more guidance on designing forms in SurveyCTO, browse our product documentation.
Do you have something interesting or valuable that you’d like to share with your fellow SurveyCTO users? Reach out to info@surveycto.com to inquire about writing a guest blog post.


